Git jest aktualnie jednym z tych narzędzi, które jest niemal niezbędne podczas rozwijania aplikacji. Ten niezwykle popularny system kontroli wersji jest stosunkowo łatwy do nauczenia się oraz zaimplementowania w naszych projektach. Jednym z pierwszych pytań, które powstają zaraz po opanowaniu Gita, jest – „No dobra, ale jak tego teraz dobrze używać?”. Nieprzemyślane commitowanie, branchowanie, mergowanie wszystkiego do mastera może spowodować, że nie wykorzystamy w pełni potencjału drzemiącego w Gicie. Dobrym pomysłem jest zaczęcie od stosowania sprawdzonych już rozwiązań. W przypadku pracy z Gitem mamy obecnie dwa bardzo popularne podejścia: Git Flow oraz GitHub Flow. W tym artykule skupimy się na nieco starszym i troszkę bardziej rozbudowanym schemacie, czyli Git Flow. GitHub Flow zostanie omówiony w oddzielnym wpisie.
Czym jest „flow”?
"Flow" to nic innego jak schemat pracy z Gitem. Jest to zestaw reguł, które określają, jak powinniśmy pracować z naszym repozytorium. "Flow" jest ustalonym i znanym sposobem na to, jak w tworzonym przez nas programie wprowadzać nowe funkcjonalności, poprawiać błędy oraz wypuszczać nowe wersje na środowiska produkcyjne. Tylko tyle i aż tyle. Jednak bez ustalonego schematu postępowania i przy stosowaniu wolnej amerykanki, możemy narobić w naszych repozytoriach niezły bałagan.

Git Flow
Git Flow został przedstawiony w 2010 roku i był jednym z pierwszych sposobów ustandaryzowania pracy z gitem. Co ciekawe, nie była to jakaś wielka praca naukowa, a jedynie post na blogu 🙂. Oryginalny wpis, od którego wszystko się zaczęło można znaleźć pod tym linkiem – A successful Git branching model.
Pomysł ten został bardzo dobrze przyjęty i w niemal niezmienionej formie funkcjonuje do dzisiaj. Należy pamiętać o tym, że model ten został przedstawiony ponad 10 lat temu. Sposób rozwoju oprogramowania nieco wtedy różnił się od współczesnego podejścia. Jeżeli działasz w środowisku CI/CD i nowe wersje twojej aplikacji są wypuszczane niemal codziennie, to Git Flow nie będzie dobry wyborem.
W przypadku Git Flow, mamy do czynienia z tzw. releasami funkcjonalności, nad którymi pracowaliśmy w ostatni czasie. Tak więc nasza aplikacja raz na jakiś czas zostaje uzupełniona o kilka mniejszych bądź jakiś jeden bardziej znaczący feature. Release taki może powstawać przykładowo podczas jednego dwutygodniowego sprintu (korzystając tutaj z terminologii Scrum).
Nie wchodząc w szczegóły dotyczących metodyk wytwarzania oprogramowania, zobaczmy, jak w całości wygląda jeden cykl pracy z wykorzystanie Git Flow.
Jak działa Git Flow?
Gałęzie
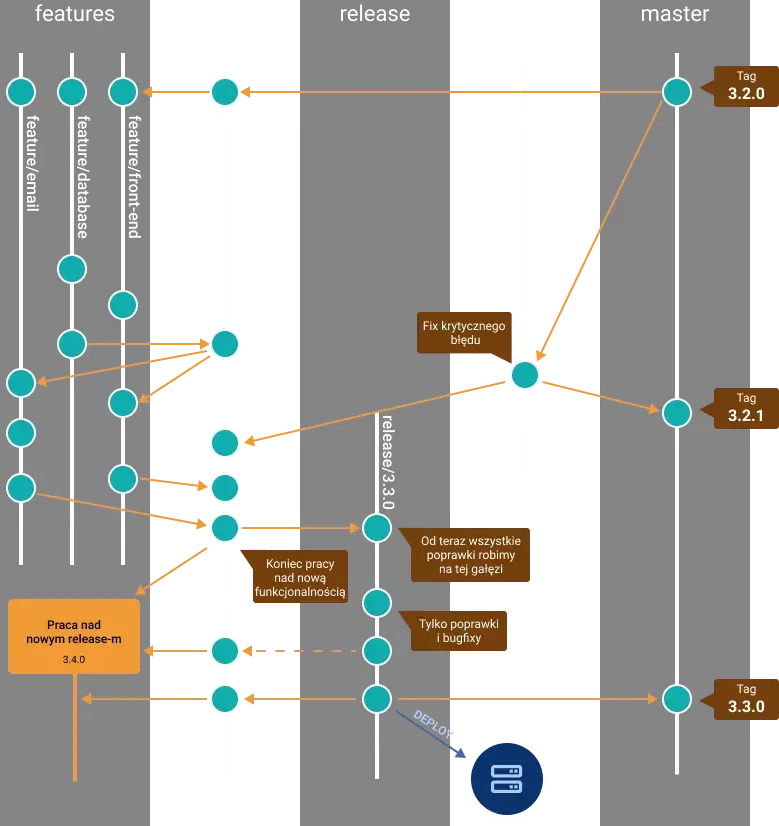
Pierwsza rzecz, którą należy zrobić, aby wdrożyć model Git Flow, to odpowiednio uporządkować gałęzie w swoim repozytorium. W tym przypadku będziemy operować na pięciu rodzajach branchy:
- master – produkcyjna wersja aplikacji. Do tego brancha będziemy mergować tylko te zmiany, które już zostały wydane na produkcję oraz krytyczne hotfixy.
- hotfix – jedyna gałąź bazująca ma masterze. To właśnie ona służy do szybkiego naprawiania krytycznych błędów występujących na produkcji.
- release – na tym branchu przygotowywany jest release kolejnej wersji aplikacji. To właśnie wersja aplikacji z tego brancha trafia na produkcję.
- develop – gałąź ta jest „nieoficjalnym” masterem podczas pracy nad releasem. Z tego brancha programiści tworzą swoje gałęzie robocze i do niego mergują (rebase-ują) swoją pracę. Gdy praca nad wszystkimi - funkcjonalnościami w danym releasie jest gotowa, branch ten jest mergowany do gałęzi „release”.
- gałęzie robocze (features) – na tych gałęziach pracujemy na co dzień i tworzymy nowe funkcjonalności.
Zakładamy, że wszystkie wymienione branche są już stworzone i w masterze znajduje się aktualna wersja naszej aplikacji. Wiemy również, że w najbliższym releasie zaplanowane jest dodanie nowej strony z formularzem kontaktowym. Użytkownik aplikacji może za jego pomocą wysłać ogólne zapytanie do działu obsługi klienta. Zapytanie takie jest zapisywane w bazie danych i wysyłane mailem na odpowiednią skrzynkę pocztową.
Jak powinna wyglądać praca nad taką funkcjonalnością przy użyciu Git Flow? Prześledźmy poszczególne kroki.
1. Przygotowanie zadań
Jak widać będziemy mieli tutaj zarówno prace na "froncie" jak i na "backendzie". Czeka nas przygotowanie formularza, zapis zapytania oraz wysyłka maila. Oczywiście jest to tylko przykładowe rozwiązanie – interesuje nas tylko jak to poprawnie przeprowadzić w Gicie.
Upewniamy się, czy nasz obecny develop zawiera aktualną wersję aplikacji z mastera i bierzemy się do pracy.

2. Praca nad zadaniami
Mamy trzy zadania i trzech programistów, więc każdy z nich tworzy własną gałąź roboczą i implementuje swoją część zadania. W międzyczasie oczywiście aktualizuje swoje branche o nowe commity, które pojawiły się w gałęzi develop.
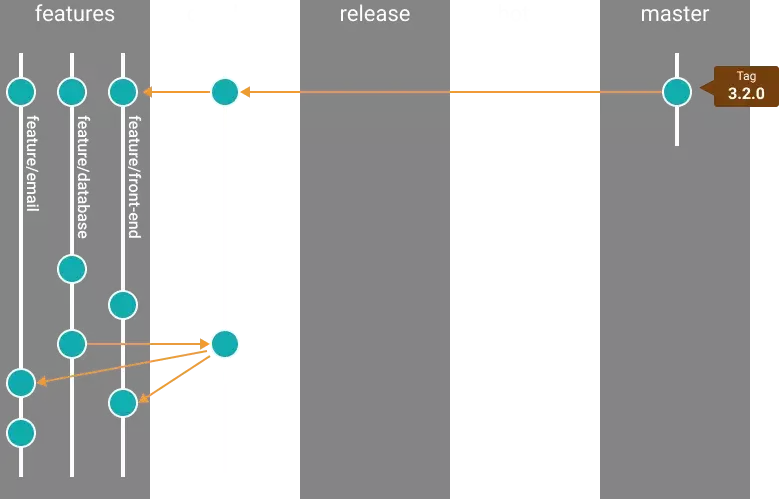
3. Pożar 🔥🔥🔥
Nasza praca nad nowym releasem idzie zgodnie z planem, ale w międzyczasie okazało się, że nasz formularz rejestracji z jakiegoś powodu nie przyjmuje adresów e-mail z poczty @gmail.com. Jest to błąd, który nie został wyłapany podczas tworzenia poprzedniego releasu i uniemożliwia stworzenia konta bardzo dużej liczbie użytkowników. Musimy to szybko naprawić. Odstawiamy więc na chwilę pracę nad formularzem i przenosimy się na branch hotfixes. Zaczynamy pracę, wychodząc z mastera, naprawiamy wszystkie błędy i umieszczamy poprawioną już wersję aplikacji na serwerach produkcyjnych. Po zakończeniu prac nie zapominamy o tym, aby nasza poprawka trafiła do mastera oraz do developa. Pożar został ugaszony możemy wracać do pracy nad releasem.

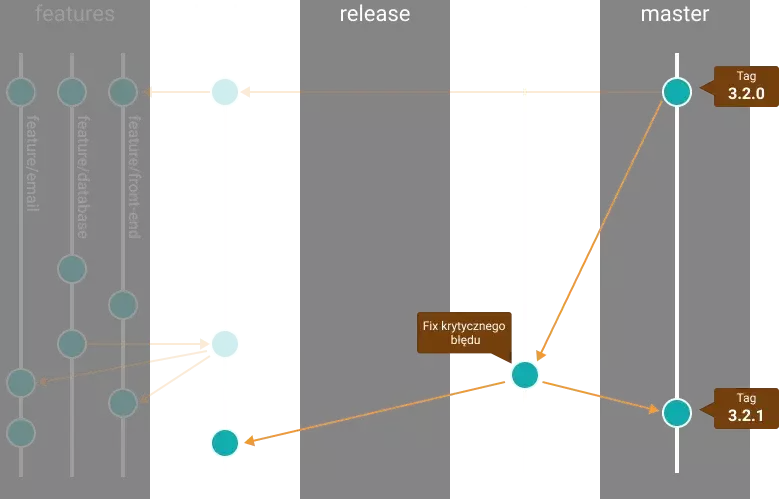
4. Przygotowanie release-u
Gdy wszyscy już ukończą pracę nad swoimi zadaniami i w branchu develop znajduje się już działający formularz kontaktowy, przechodzimy do przygotowania release-u. Z developa tworzymy nową gałąź np. release/3.3.0 i od teraz wszystko, co związane jest z funkcjonalnościami wymaganymi w tym release-ie dzieje się już na tym branchu. Wliczamy w to również wszelkie poprawki i bugfixy.
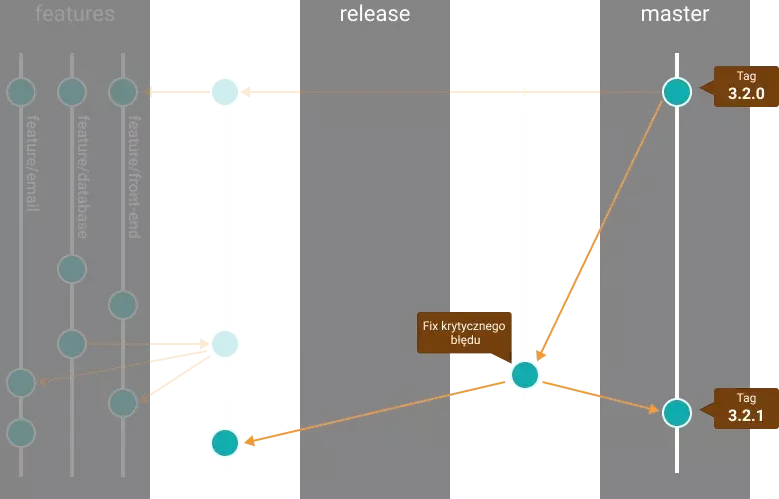
5. Release branch
Kod, który znajduje się na branchu release-owym powinien zostać umieszczony i testowany na środowisku, które jest jak najbardziej zbliżone do środowiska produkcyjnego. W przypadku wykrycia jakichś błędów (bugów) są one naprawiane bezpośrednio na tym samym branchu. Przechodzimy teraz przez fazy test ➡️ fix ➡️ deploy tak długo, aż nasz release będzie w końcu gotowy do wprowadzenia go na produkcję.
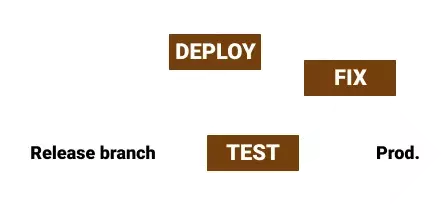
Jeżeli jedna z poprawek jest dość istotna z punktu widzenia całej aplikacji, nic nie stoi na przeszkodzie, aby w międzyczasie zaktualizować developa o commity z release brancha jeszcze zanim kod trafi na produkcję.
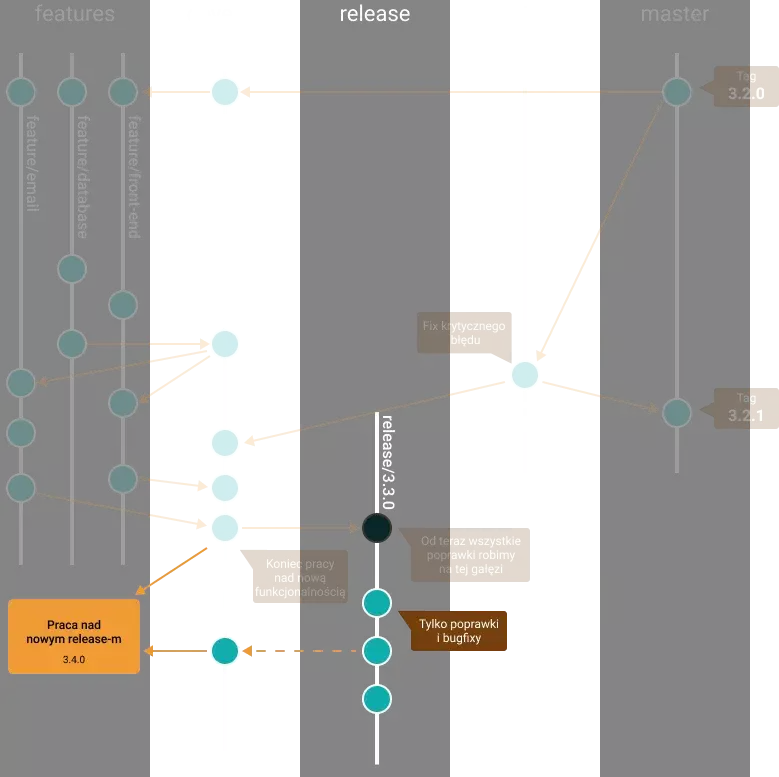
Co w tym czasie robią pozostali członkowie zespołu?

6. Nowy release
Oczywiście, że mogą już zacząć pracować nad kolejnym release-m 🙂. Branch develop zawiera najnowszą wersję aplikacji, więc spokojnie można zacząć już pracę nad kolejnymi funkcjonalnościami. Wszelkie poprawki, które zostaną ewentualnie wprowadzone na release branchu i tak trafią do developa po udanym deployu na produkcję. Jako że będą to pewnie małe zmiany, nie powinny nam jakoś bardzo przeszkodzić w pracy (czyt. konflikty będą łatwe do rozwiązania 🙂).
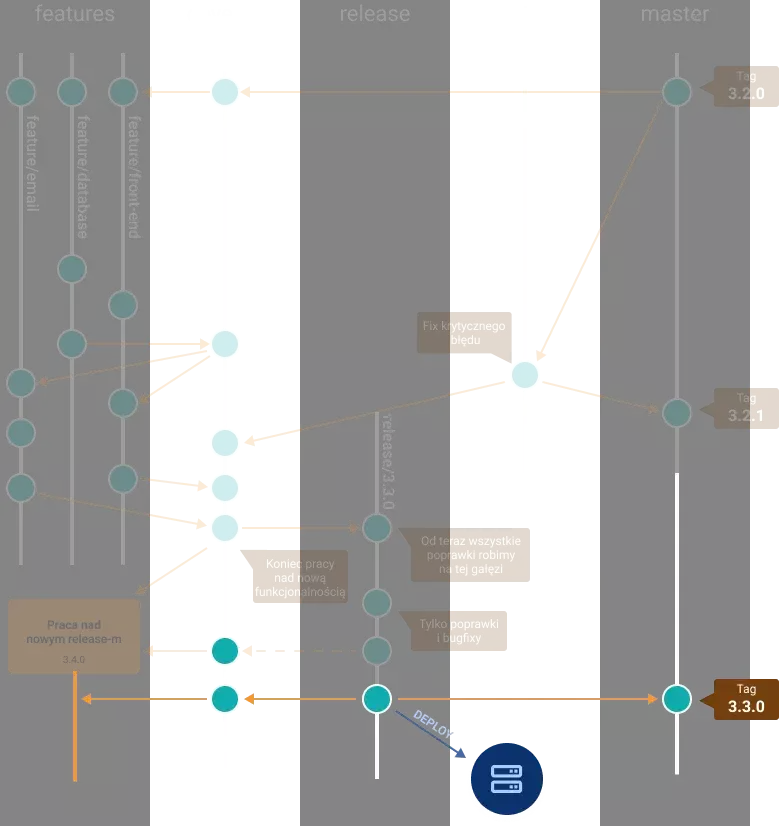
7. Wyjście na produkcję
Aplikacja działa poprawnie, wszystkie testy świecą się na zielono i nie mamy piątkowego popołudnia, więc możemy wychodzić z naszą najnowszą funkcjonalnością na produkcję. W momencie, gdy deploy odbył się bez problemów oraz aplikacja działa w porządku, możemy przejść do ostatniej fazy Git Flow.
Tą fazą jest aktualizacja gałęzi develop oraz master o commity, które zostały wydane wraz z ostatnim releasem. W masterze dodatkowo dodajmy tag odpowiadający wersji releasu. Dzięki temu w masterze trzymamy tylko ten kod, który był kiedykolwiek deployowany. W przypadku problemów z nową wersją aplikacji zawsze możemy przywrócić jej poprzednią działającą wersję.
Podsumowanie
Git Flow jak widać, nie należy do najłatwiejszych rozwiązań. Na pewno jest dość bezpieczny i pomaga nam wyłapywać sporo błędów jeszcze w trakcie developmentu i samego testowania. Ze względu na swoją specyfikę sprawdzi się on najlepiej w przypadku, gdy nowe funkcjonalności bądź fixy mało krytycznych błędów wypuszczamy z pewną regularnością. Przykładowo właśnie po każdym wspomnianym już wcześniej dwutygodniowym sprincie.
Git Flow powstał w czasach, gdy taka forma tworzenia i wydawania oprogramowania była niemalże standardem. Ułatwiał on więc bardzo życie programistom. Współcześnie coraz większą rolę odgrywają aplikacje webowe. W ich przypadku na porządku dziennym jest wykorzystanie ciągłego dostarczania (continuous delivery) nowych, małych funkcjonalności oraz poprawek. Aplikacje takie nie są zazwyczaj przywracane do poprzednich wersji, a powstające błędy są na bieżąco naprawiane.
W takiej sytuacji stosowanie Git Flow będzie bardzo nieefektywne. Potrzebne jest łatwiejsze i szybsze podejście. Tym podejściem jest GitHub Flow, który jak sama nazwa wskazuje, został stworzony przez GitHuba na potrzeby ich codziennych (czasem nawet kilkukrotnych w ciągu jednego dnia) deployów. Tym zagadnieniem jednak zajmiemy się już w oddzielnym wpisie.
Masz uwagi lub sugestie do tego wpisu?